A comparative study of the efficacy of CFP and OCT in oculomic tasks with identical training and evaluation details (Applified Abstract)
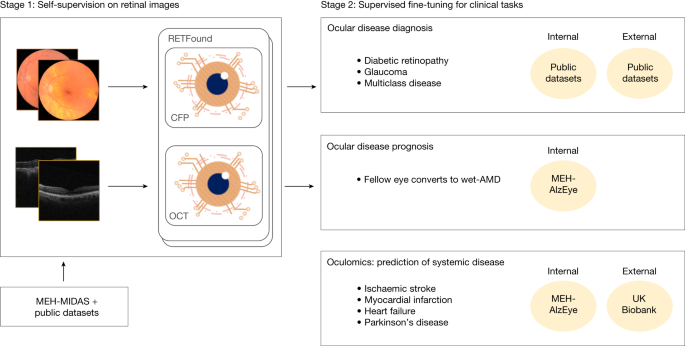
The experiments show that both modalities of CFP and OCT have unique ocular and systemic information encoded that is valuable in predicting future health states. Some image sources that are used to diagnose ocular diseases include, but are not limited to, the use of OCT for wet-AMD. However, such knowledge is relatively vague in oculomic tasks as (1) the markers for oculomic research on different modalities are under exploration and (2) it requires a fair comparison between many modalities with identical evaluation settings. In this work, we investigate and compare the efficacy of CFP and OCT for oculomic tasks with identical training and evaluation details (for example, train, validation and/or test data splitting is aligned by anonymous patient IDs). We notice that the models with CFP and OCT achieve unequal performances in predicting systemic diseases (Fig. 3 and Supplementary Table 3), suggesting that CFP and OCT contain different levels of information for oculomic tasks. For instance, in 3-year incidence prediction of ischaemic stroke, RETFound with CFP performs better than with OCT on both MEH-AlzEye (internal evaluation) and UK Biobank (external evaluation). RETFound with OCT has better performance in internal evaluation for Parkinson’s disease. Some of the disorders of ageing may manifest certain early markers on theretinal images. A practical implication for health service providers and imaging device manufacturers is to recognize that CFP has continuing value, and should be retained as part of the standard retinal assessment in eye health settings. This observation encourages Oculomic research to investigate the relationship between systemic health and information contained in multiple image modalities.
Instead, the scientists used a method similar to the one used to train large-language models such as ChatGPT. That AI tool harnesses myriad examples of human-generated text to learn how to predict the next word in a sentence from the context of the preceding words. In the same kind of way, RETFound uses a multitude of retinal photos to learn how to predict what missing portions of images should look like.
Pearse Keane, an osmone at Moorfields Eye Hospital in London who co-authored a paper about the tool, said it learns what a retina looks like after millions of images. A foundation model is a model which can be adapted for many different tasks, and this forms the cornerstone of the model.
A person’s retinas can offer a window into their health, because they are the only part of the human body through which the capillary network, made up of the smallest blood vessels, can be observed directly. If you have a disease that affects your blood vessels, we can show you in images.
A Comparison of RETFound’s Masked Autoencoder with Contrastive SSL Models for Retinal Detection
A clinical researcher studying responsible innovation in the fields of artificial intelligence and machine learning says using unlabelled data to initially train the model is a major roadblock for researchers. Radiologist Curtis Langlotz, director of the Center for Artificial Intelligence in Medicine and Imaging at Stanford University, in California, agrees. He says that label efficiency has become a coin of the realm due to the expensive labels for medical data.
RETFound’s techniques were used to look at other types of medical images. “It will be interesting to see whether these methods generalize to more complex images,” Langlotz says — for example, to magnetic resonance images or computed tomography scans, which are often three- or even four-dimensional.
The model has been made publicly available and the hope is that it can be adapted and trained for the different populations of patients in different countries. They could fine-tune the algorithm using data from their country, and have it more suited for their use.
“This is tremendously exciting,” Liu says. She said using RETFound as the basis for other models to detect diseases came with a risk. That’s because any limitations embedded in the tool could leak into future models that are built from it. “It is now up to the authors of RETFound to ensure its ethical and safe usage, including transparent communication of its limitations, so that it can be a true community asset.”
RETFound maintains competitive performance when substituting various contrastiveSSL approaches into the framework. It seems that the generative approach using the masked autoencoder generally outperforms the contrastive approaches, including SwAV, SimCLR, MoCo-v3 and DINO. However, it is worth noting that asserting the superiority of the masked autoencoder requires caution, given the presence of several variables across all models, such as network architectures (for example, ResNet-50 for SwAV and SimCLR, Transformers for the others) and hyperparameters (for example, learning rate scheduler). Our comparison demonstrates that the combination of powerful network architecture and complex pretext tasks can produce effective and general-purpose medical foundation models, aligning with the insights derived from large language models in healthcare49,50. Furthermore, the comparison further supports the notion that the retinal-specific context learned from the masked autoencoder’s pretext task, which includes anatomical structures such as the optic nerve head and retinal nerve fibre layer (as shown in Extended Data Fig. 6a), indeed provides discriminative information for the detection of ocular and systemic diseases.
There is a significant fall in performance when adapted models are tested against new cohorts that differ in the demographic profile, and even on the imaging devices that were used (external evaluation phase). This phenomenon is found in the evaluation of disease diagnosis and prediction. 3a). For example, the performance on ischaemic stroke drops (RETFound’s AUROC decreases by 0.16 with CFP and 0.19 with OCT). The different age and ethnicities of the internal and external validation cohort, the UK Biobank and the MEH-Alz Eye are likely to be a factor in the performance drop in the challenging oculomic tasks. Compared to other models, RETFound achieves significantly higher performance in external evaluation in most tasks (Fig. It’s good generalizability as well as different ethnicities.