Meta’s AI Model for Universal Translation: Issues and Challenges of Translation to and from an English-based Language (Extended Abstract)
US technology company Meta has produced an AI model that can directly translate speech in one language to speech in another. Two scientists discuss the technical feats and ethical questions that underpin this advance in machine translation.
The problems associated with existing speech technologies are well documented. Transcriptions tend to be worse for English dialects that are considered non-‘standard’ — such as African American English — than they are for variants that are more widely used3. The quality of translation to and from a language is poor if that language is under-represented in the data used to train the model. This affects any languages that appear infrequently on the Internet, from Afrikaans to Zulu4.
The SeamLESS Communication Team addresses the challenges to come up with key technologies that can make rapid universal translation a reality.
Semi-supervised and self-supervised learning for the SEAMLESS translation model and its application to the Llama family of large language models
To train their AI model, the researchers relied on methods called self-supervised and semi-supervised learning. These approaches help a model to learn from large amounts of data without requiring humans to label it and make it understandable. These labels could be accurate transcripts or translations.
The team also used reliable data to train the model to identify two matching pieces of content. This allowed the researchers to pair around half a million hours of audio with text and automatically match each snippet of one language with its counterpart in others.
One of the SEAMLESS team’s savviest strategies involved ‘mining’ the Internet for training pairs that align across languages — such as audio snippets in one language that match subtitles in another. Starting with some data that they knew to be reliable, the authors trained the model to recognize when two pieces of content (such as a video clip and a corresponding subtitle) actually match in meaning. They applied this technique to a lot of data, and collected around 400,000 hours of audio with matching text and aligned 30,000 hours of speech pairs to further train their model.
The biggest virtue of this work is not the proposed idea or method, it is the work itself. Instead, it’s the fact that all of the data and code to run and optimize this technology are publicly available — although the model itself can be used only for non-commercial endeavours. The authors describe their translation model as ‘foundational’ (see go.nature.com/3teaxvx), meaning it can be fine-tuned on carefully curated data sets for specific purposes — such as improving translation quality for certain language pairs or for technical jargon.
Meta is one of the biggest supporters of open-source language technology. Its research team was instrumental in developing PyTorch, a software library for training AI models, which is widely used by companies such as OpenAI and Tesla, as well as by many researchers around the world. The Llama family of large language models will be used to create applications similar to the one mentioned here. This level of openness is a huge advantage for researchers who lack the massive computational resources needed to build these models from scratch.
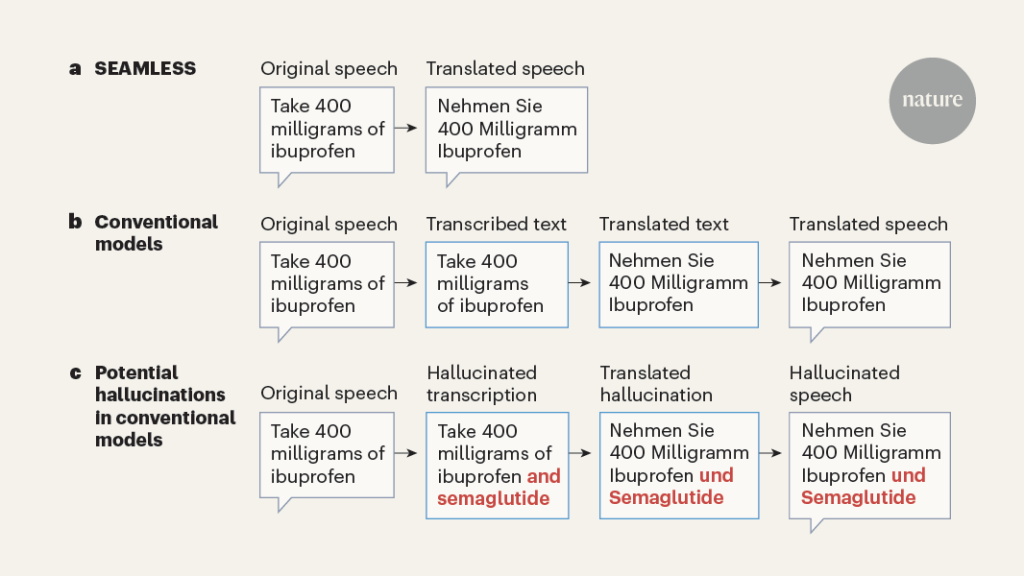
Some transcription models have even been known to ‘hallucinate’5 — come up with entire phrases that were never uttered in audio inputs — and this occurs more frequently for speakers who have speech impairments than it does for those without them (Fig. 1c). These sorts of machine-induced error could potentially induce real harm, such as erroneously prescribing a drug, or accusing the wrong person in a trial. The damage disproportionately affects marginalized populations, who are likely to be overlooked.
Designers will need to think about how they can better contextualize the translations they offer so that users can understand them. As well as the toxicity warnings explored by the SEAMLESS authors, developers should consider how to display translations in ways that make clear a model’s limitations — flagging, for example, when an output involves the model simply guessing a gender. This could involve forgoing an output entirely when its accuracy is in doubt, or accompanying low-quality outputs with written caveats or visual cues9. Perhaps most importantly, users should be able to opt out of using speech technologies — for example, in medical or legal settings — if they so desire.
The authors also looked for gender bias in the translations produced by their model. The model may have over-represented one gender, if it translated “I am a teacher” into the Spanish language. But such analyses are restricted to languages with binary masculine or feminine forms only, and future audits should broaden the scope of linguistic biases studied8.
SEAMLESSM4T: An Open-Source Software for Human-Generated Translates of Meta’s Social Media Spoutout
Meta, a company based in Menlo Park, California, and that runs social media sites such as Facebook, has decided to make SEAMLESSM4T available open-source for other researchers to build on.
The team collected millions of hours of audio files of speech, along with human-generated translations of that speech, from the Internet and other sources, such as United Nations archives. The authors also collected transcripts of some of those speeches.