The effect of neuronal response on words with high and low surprisal, based on pre-trained long short-term memory recurrent neural networks
The words that the same set of neurons reacted to fell into the categories of actions or words associated with people. The team found that words that the brain might associate with one another, such asduck andegg, triggered some of the same cells. Words with similar meanings, such as ‘mouse’ and ‘rat’, triggered patterns of neuronal activity that were more similar than the patterns triggered by ‘mouse’ and ‘carrot.’ The group of cells that respond to words associated with concepts such as above and behind did so.
Finally, to ensure that our results were not driven by any particular participant(s), we carried out a leave-one-out cross-validation participant-dropping procedure. Here we repeated several of the analyses, but now remove individual participants from every single iteration. If any group of participants who contributed significantly to the results were removed, it would have an impact on the results. The 2 test was used to evaluate differences in the distribution of neurons among participants.
Next we examined how surprisal affected the ability of the neurons to accurately predict the correct semantic domains on a per-word level. To achieve this, we used models similar to that described above, but now divided decoding performance between words that exhibited high and low surprisal. Therefore, if the meaning representations of words were indeed modulated by sentence context, words that are more predictable on the basis of their preceding context should exhibit a higher decoding performance (that is, we should be able to predict their correct meaning more accurately from neuronal response).
in which P represents the probability of the current word (w) at position i within a sentence. Here, a pretrained long short-term memory recurrent neural network was used to estimate P(wi | w1…wi−1)73. On the basis of the preceding context, words that are more predictable would have a low surprisal compared to words that are poorly predictable.
Semantic encoding during language comprehension at single-cell resolution: an empirical P value from random shuffling of SVCs and bootstrap data
There are 100 times the left side of the improvement.
(x) is the neural activity and is related to the classification of individual words. The regularization parameter C was set to 1. We used a balanced class weight and a linear kernel to account for the inhomogeneous distribution of words. Finally, after the SVCs were modelled on the bootstrapped training data, decoding accuracy for the models was determined by using words randomly sampled and bootstrapped from the validation data. We further generated a null distribution by calculating the accuracy of the classifier after randomly shuffling the cluster labels on 1,000 different permutations of the dataset. These models therefore together determine the most likely semantic domain from the combined activity patterns of all selective neurons. An empirical P value was then calculated as the percentage of permutations for which the decoding accuracy from the shuffled data was greater than the average score obtained using the original data. The statistical significance was determined at P value < 0.05.
There is alimits_rmi
Source: Semantic encoding during language comprehension at single-cell resolution
The SI of a Neuron: a Function of Semantic Encoding During Language Comprehension at Single-Cell Resolution
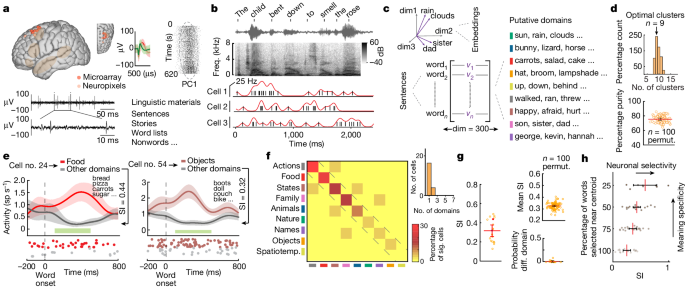
Next we determined the SI of each neuron, which quantified the degree to which it responded to words within specific semantic domains compared to the others. Here SI was defined by the cell’s ability to differentiate words within a particular semantic domain (for example, ‘food’) compared to all others and reflected the degree of modulation. Each neuron had its SI calculated.
in which ({{\rm{FR}}}{{\rm{domain}}}) is the neuron’s average firing rate in response to words within the considered domain and ({{\rm{FR}}}{{\rm{other}}}) is the average firing rate in response to words outside the considered domain. SI reflects the magnitude of effect based on the difference between activity for each neuron in their preferred semantic domain. Therefore, the output of the function is bounded by 0 and 1. An SI of 0 would mean that there is nothing different between the activity in the neuron and the activity in one of the semantic domains, whereas an SI of 1.0 would say that the neuron changed its potential activity only when hearing words.
rmSI is an abbreviation for left and right.
Source: Semantic encoding during language comprehension at single-cell resolution
Semantic Clustering of Words in a Story Narrative Based on Cosine Distances and k-Means
We used the spherical clustering algorithm to group words heard by the participants into representative semantic domains and used the cosine distance between their representative vectors to figure out how big the group was. The new space gave us a chance to get distinct word clusters. This approach therefore grouped words on the basis of their vectoral distance, reflecting the semantic relatedness between words37,40, which has been shown to work well for obtaining consistent word clusters34,71. The k-means procedure was repeated 1000 times to generate a distribution of the optimal number of cluster values. For each iteration, a silhouette criterion for cluster number between 5 and 20 was calculated. The cluster with the greatest average criterion value (as well as the most frequent value) was 9, which was taken as the optimal number of clusters for the linguistic materials used34,37,43,44.
In which the total number of words is divided by 9; Omega _i is a cluster from the set of new clusters and n is the total number of words. Finally, to confirm the separability of the clusters, we used a standard d′ analysis. The d′ metric shows the difference between the different distances for all words in a particular cluster compared to the other words. 2b).
Excerpts from a story narrative were introduced at the end of recordings to evaluate for the consistency of neuronal response. Here, instead of the eight-word-long sentences, the participants were given a brief story about the life and history of Elvis Presley (for example, “At ten years old, I could not figure out what it was that this Elvis Presley guy had that the rest of us boys did not have”; Extended Data Table 1). This story was selected because it was naturalistic, contained new words, and was stylistically and thematically different from the preceding sentences.
A word-list control was used to evaluate the effect of sentence context. These word lists (for example, “to pirate with in bike took is one”; Extended Data Table 1) contained the same words as those given during the presentation of sentences and were eight words long, but they were given in a random order, therefore removing any effect that linguistic context had on lexico-semantic processing.
A meaning-specific change in neural activity could be evaluated with Homophone pairs. All of the homophones were created from sentence experiments in which different words came from different semantic domains. Homophones were used as the word embeddings gave a different kind of vector for each unique token than for each token sense.
The participants were presented with eight-words long sentences that covered many different topics and gave a wide range of semantically diverse words. To confirm that the participants were paying attention, a brief prompt was used every 10–15 sentences asking them whether we could proceed with the next sentence (the participants generally responded within 1–2 seconds).
The linguistic materials were given to the participants in audio format using a Python script utilizing the PyAudio library (version 0.2.11). The Alpha Omega rig has two microphones integrated that are used for high-fidelity temporal alignment with neuronal data. Audio recordings were annotated in semi-automated fashion (Audacity; version 2.3). Audio recordings were made using a portable audio recorder with a microphone and a 44 percent sampling rate (TASCAM DR-404). The time offset was determined by the amplitude of each session recording and pre-recorded linguistic materials that were related to the activity. Each word token and its timing was manually validation for additional confirmation. Together, these measures allowed for the millisecond-level alignment of neuronal activity with each word occurrence as they were heard by the participants during the tasks.
The comparison to the single-neuronal data was done separately. These MUAs reflect the combined activities of multiple putative neurons recorded from the same electrodes as represented by their distinct waveforms57,69,70. These MUAs were obtained by removing spikes from the baseline noise. Unlike for the single units, the spikes were not separated on the basis of their waveform morphologies.
For the silicon microelectrode recordings, sterile Neuropixels probes31 (version 1.0-S, IMEC, ethylene oxide sterilized by BioSeal) were advanced into the cortical ribbon with a manipulator connected to a ROSA ONE Brain (Zimmer Biomet) robotic arm. The probes (width: 70 µm, length: 10 mm, thickness: 100 µm) consisted of 960 contact sites (384 preselected recording channels) that were laid out in a chequerboard pattern. An IMEC headstage was installed in a National Instruments PXIe 10701 Chassis and connected to it through a multiplexed cable. OpenEphys is used to record the action potential band on a computer connected to the PXIe acquisition module. Once putative units were identified, the Neuropixels probe was held in position briefly to confirm signal stability (we did not screen putative neurons for speech responsiveness). Additional description of this recording approach can be found in refs. 20,30,31. After completing single-neuronal recordings from the cortical ribbon, the Neuropixels probe was removed, and subcortical neuronal recordings and deep brain stimulator placement proceeded as planned.
Language Comprehension Using Single Neuronal Recordings and Intraoperative Neurophysiology: A Randomized Study Using a Multidisciplinary Team
Once a patient is consented to surgery and given informed consent, their candidacy for study participation was reviewed by a team of experts who looked at their age, right-hand dominant personality and ability to speak English. To evaluate for language comprehension and the ability to participate in the study, the participants were given randomly samples of sentences and then asked questions such as “What was placed in the bottle?” Participants that could not answer all questions on the test were excluded from consideration. All participants gave informed consent to participate in the study and were free to withdraw at any point without consequence to clinical care. 13 people wereEnrolled in theExtended Data Table 1. Randomization and blinding were not used.
The studies and procedures were done in adherence to Harvard Medical School guidelines, as well as the Massachusetts General Hospital Institutional Review Board. All participants included in the study were scheduled to undergo planned awake intraoperative neurophysiology and single-neuronal recordings for deep brain stimulation targeting. Consideration was made for surgery with the help of a multidisciplinary team. The decision was made on its own. All microelectrode entry points and placements were made independently of any study consideration.
Recording from neurons is much faster than using imaging; understanding language at its natural speed, he says, will be important for future work developing brain–computer interface devices that restore speech to people who have lost that ability.
As participants listened to multiple short sentences containing a total of around 450 words, the scientists recorded which neurons fired and when. Williams says that around two or three distinct neurons lit up for each word, although he points out that the team recorded only the activity of a tiny fraction of the prefrontal cortex’s billions of neurons. The researchers looked at the similarities between the words.
Researchers were able to determine what people were hearing by observing their brains. They were able to say that a sentence contained an animal, an action and a food at the same time.
Williams suggests the human brain assigns meanings to words in the same way the brain assigns categories to people.
Previous research2 has studied this process by analysing images of blood flow in the brain, which is a proxy for brain activity. Researchers could map word meaning to certain regions of the brain using this method.